ODC with AWS S3 - Backend to S3
Securely Transfer Files Between Your Backend and S3 with REST and Pre-Signed URLs

Throughout my diverse career, I've accumulated a wealth of experience in various capacities, both technically and personally. The constant desire to create innovative software solutions led me to the world of Low-Code and the OutSystems platform. I remain captivated by how closely OutSystems aligns with traditional software development, offering a seamless experience devoid of limitations. While my managerial responsibilities primarily revolve around leading and inspiring my teams, my passion for solution development with OutSystems remains unwavering. My personal focus extends to integrating our solutions with leading technologies such as Amazon Web Services, Microsoft 365, Azure, and more. In 2023, I earned recognition as an OutSystems Most Valuable Professional, one of only 80 worldwide, and concurrently became an AWS Community Builder.
This article explains how to upload and download files from your OutSystems Developer Cloud application's backend to a private Amazon Simple Storage Service (S3) bucket.
By default, an S3 bucket is private and not accessible to the public without authorization. For S3 objects smaller than 5.5MB, you can use the PutObject action of the AWSSimpleStorage external logic connector to upload, and GetObject to download. Using this connector actions is pretty straight forward on not covered in this article.
External Logic functions have a request and response payload limit of 5.5MB, which means you cannot use these actions for larger files.
In this article, we walk through a method you can use to store and access larger files in an S3 bucket. This involves creating pre-signed URLs with the AWSSimpleStorage external logic connector and combining them with REST consume operations in your application.
This article is part of a series that explores ways to interact with Amazon S3 buckets. Be sure to read the introductory article to understand why S3 can be a valuable addition to your ODC applications and the challenges you might encounter.
Pre-signed URLs
AWS S3 pre-signed URLs offer a way to temporarily access a private object in an Amazon S3 bucket. These URLs include authentication information in the query string, allowing a user to perform a specific action, like reading or writing to an S3 object, without needing to authenticate.
One benefit is that the S3 object targeted by the pre-signed URL doesn't need to exist beforehand. This means you can create a pre-signed URL for a brand new object, allowing you to upload new objects to an S3 bucket using the URL.
When creating a pre-signed URL, you specify how the object will be accessed. This includes at least the request type (GET, PUT, etc.) and can also include additional request parameters like headers and metadata. This request is then signed with your AWS credentials, and the signature is added to the pre-signed URL along with additional parameters.
When using a pre-signed URL to request the object, it's important to execute the request with the same set of parameters specified. This means the request must be of the exact type and include the specified headers and other parameters. Otherwise, the signature validation, and therefore the object authorization, will fail.
Prerequisites
To try out the reference application, you will need the following:
S3 Bucket
AWS Credentials with a policy that allows storing and retrieving objects
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": "arn:aws:s3:::<yourbucketname>/*"
}
]
}
Configure the settings of the reference application in ODC Studio.
Make sure to configure the base URL of your S3 bucket in the Consumed REST operations tab after you create the bucket.
With all prerequisites completed, let's begin with the upload process.
Upload
Uploading a file from your application's backend to an S3 bucket involves two steps. First, we generate a pre-signed URL for a PUT request using the GetPresignedUrl action of the AWSSimpleStorage external logic connector. Then, we execute the request using a REST consume operation.
While an external logic function has a request and response limit of up to 5.5MB, this limit does not apply to REST consume operations within your application. With a REST consume operation, we can transfer much larger files to an S3 bucket.
Open the reference application in ODC Studio. On the Interface tab select the ServerSide screen.
This screen has a form on the right side with the default File Upload widget. The widget is connected to a form structure with FileName and FileData attributes that will store the selected file in memory.
When you submit the form using the Upload button, the values of FileName and FileData are used as input parameters for the Server_Upload server action, which handles the actual upload.
Server_Upload Server Action
Here the above mentioned two-step process is executed.
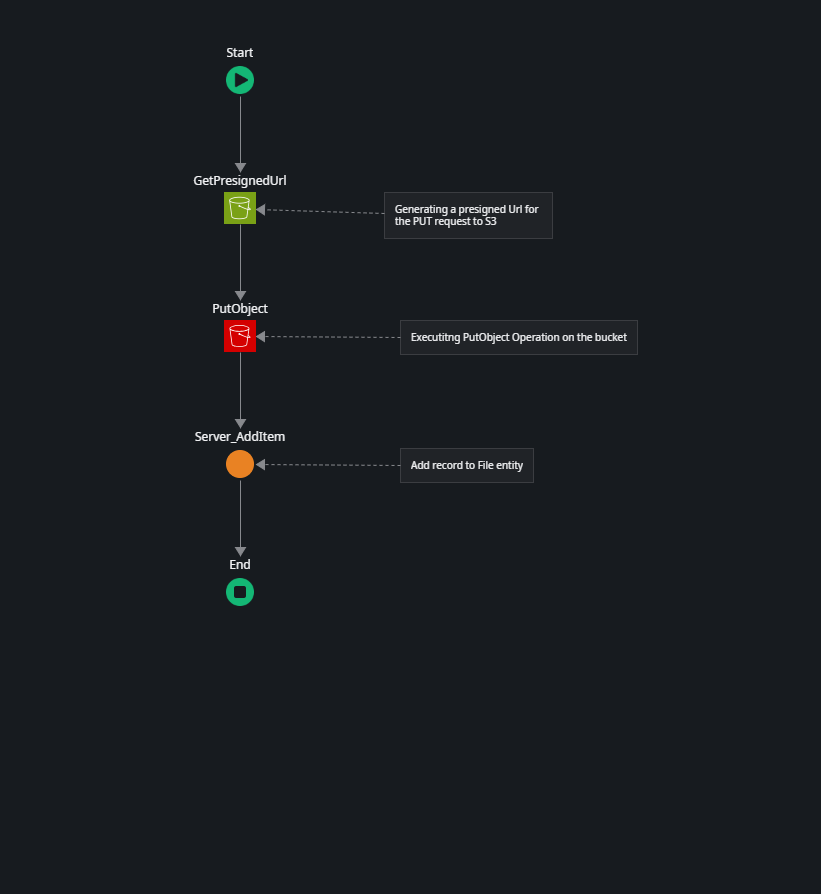
First, we generate a pre-signed URL for a PUT request to our S3 bucket using the GetPresignedUrl action of the AWSSimpleStorage external logic connector.
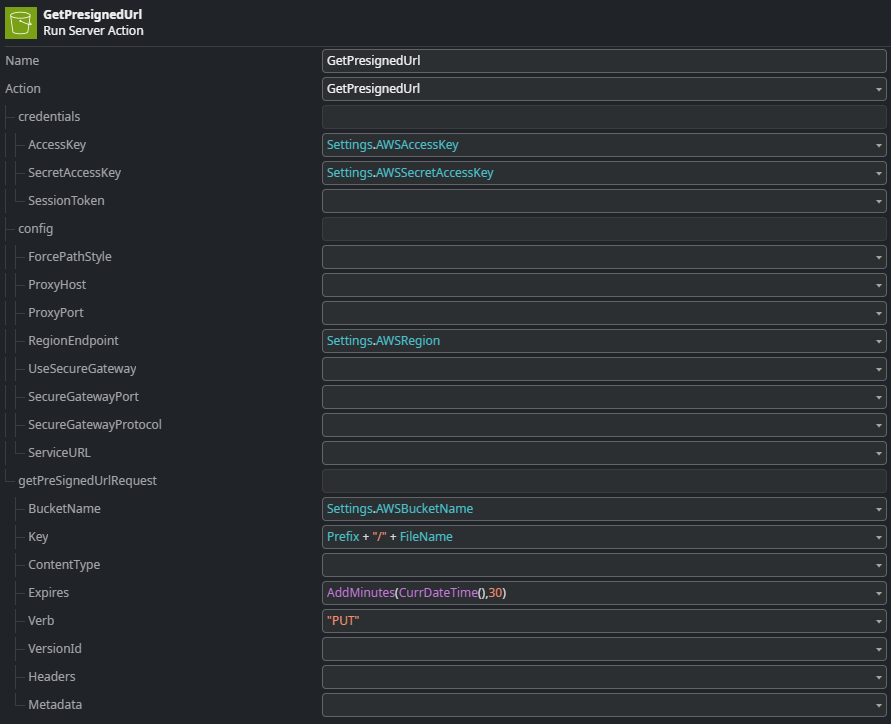
This action generates a pre-signed URL valid for 30 minutes. The GetPresignedUrl action of the connector library does not only return the full pre-signed Url, but also a deconstructed version of it with the individual elements of the Url. This is very helpful to construct the REST consume operation which is next.
Second is the PutObject REST consume operation.
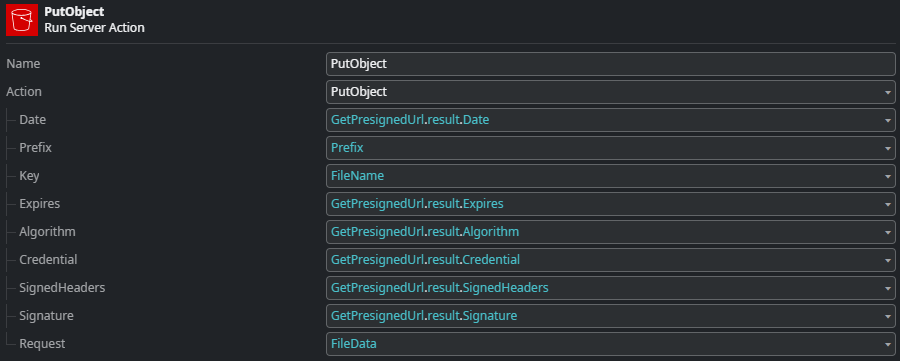
Here, we assign the individual parts of the pre-signed URL to the input parameters of the PutObject consume operation. For more details on how this part is implemented, see the section on REST Operations.
After a successful PUT of our file object, we then create a File entity record using the Server_AddItem server action.
This method lets you upload objects larger than 5.5MB to an S3 bucket from your frontend. However, there are two restrictions for OutSystems Developer Cloud applications. The maximum request payload from your frontend to the backend is 28MB, and this limit cannot be changed. The default request timeout is 10 seconds, but you can extend it to a maximum of 60 seconds. If you exceed these limits, your upload will fail.
These limits only apply between your frontend application and your backend. For example, if you are retrieving a 100MB file from an external web service via REST consume, you can use the PutObject REST consume operation to store it in an S3 bucket.
Download
Downloading an object from an S3 bucket is similar to uploading. However, it uses a generated pre-signed URL for a GET request and a GET REST consume operation to return the object content as binary data.
The ServerSide screen displays records from the File entity in a table, and each entry includes a download link. When you click the link, it triggers the Server_Download server action, using the File Identifier of the selected file as an input parameter.
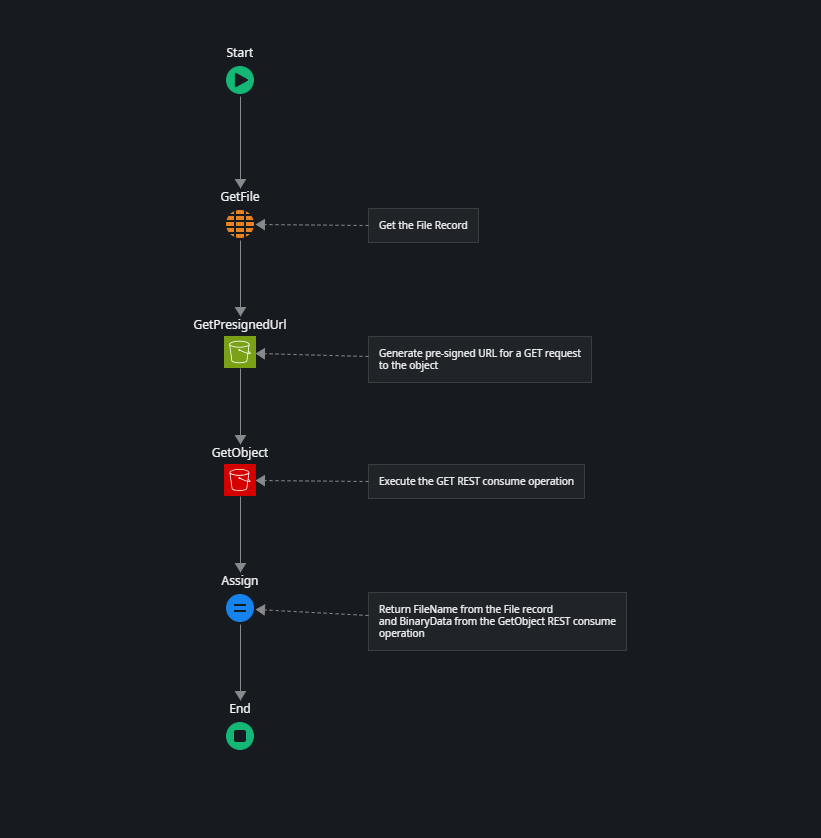
First, the details of the File record are retrieved from the entity. Then, a pre-signed URL for a GET request to the S3 object is generated.
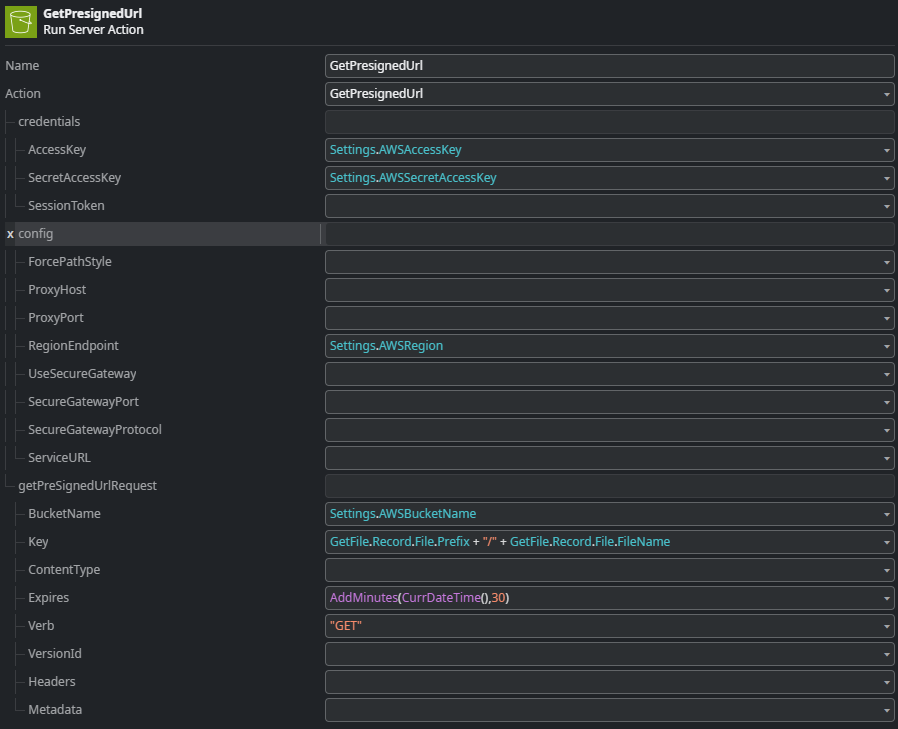
This action generates a pre-signed URL valid for 30 minutes. The GetPresignedUrl action of the connector library does not only return the full pre-signed Url, but also a deconstructed version of it with the individual elements of the Url. This is very helpful to construct the REST consume operation which is next.
Second is the GetObject REST consume operation.
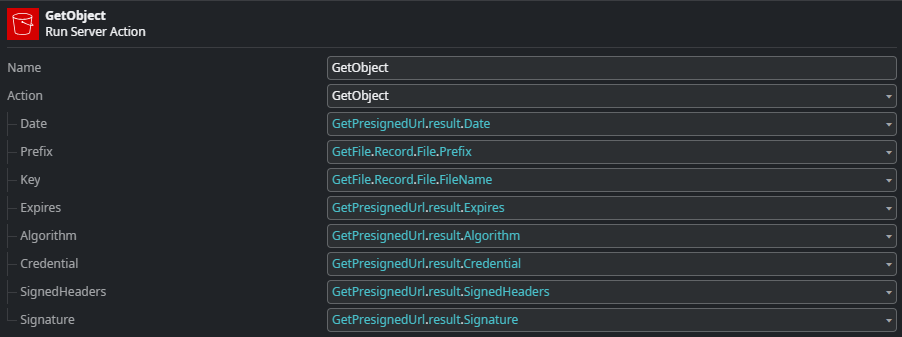
Here, we assign the individual parts of the pre-signed URL to the input parameters of the GetObject consume operation. For more details on how this part is implemented, see the section on REST Operations.
After successfully retrieving the object, we return the FileName from the File record and the binary data provided by the GetObject REST consume operation.
In our client action on the front end, we use the Download widget to download the file.
While there is a 28MB request limit from the frontend to the backend, this limit does not apply to responses. You can return binary data from your backend to your frontend that is much larger than this limit.
The reference application lets you manually create a File record for an object you uploaded directly to S3, such as through the AWS console. Try it with a file larger than 28MB.
REST Operations
Let's take a closer look at the two REST consume operations that upload (PutObject) and download (GetObject) an object from the S3 bucket.
In the Logic tab under Integrations, expand the S3 consume API. You will see three entries:
PutObject - a PUT request that uploads an object
GetObject - a GET request that downloads an object
and an OnBeforeRequest handler.
Both PutObject and GetObject are similar, except for the request type, and GetObject returns a response with binary data.
A valid pre-signed URL consists of the following query string parameters:
X-Amz-Date - The date and time when the signature was created
X-Amz-Expires - The date and time when the pre-signed URL expires
X-Amz-Algorithm - The algorithm used for the signature
X-Amz-Credential - The credentials used to sign the request
X-Amz-SignedHeaders - The request headers included in the signature
X-Amz-Signature - The computed signature
All these values can be filled in using the deconstructed pre-signed URL parameters returned by the GetPresignedUrl action of the AWSSimpleStorage external logic connector.
Besides the values for the above the REST operation takes two additional input parameters that are added to the request header: Key and Prefix.
Objects in a S3 bucket are referenced by path, where the Prefix is the path and Key is the actual object. So for example https://osdemostore.s3.eu-centra-1.amazonaws.com/myprefix1/myprefix2/mysampledocument.pdf references an object that is prefixed with myprefix1/myprefix2.
The challenge with using REST consume operations in ODC is that ODC automatically URL encodes all parameters. This means you can't simply include the prefix in your URL because ODC would automatically URL encode the forward slash (/) when having multiple prefixes. This is where we use the OnBeforeRequest handler.
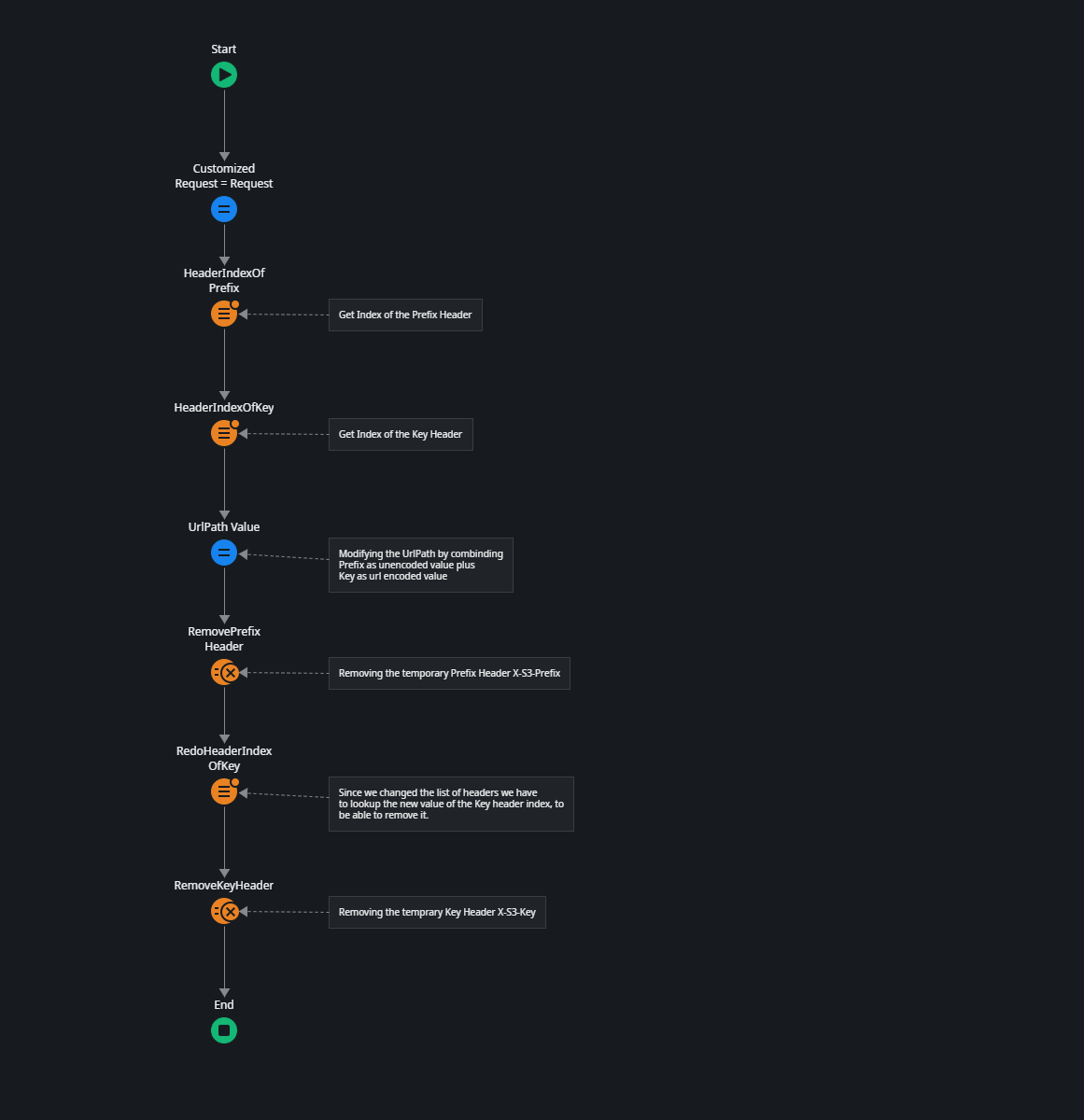
This process is a bit lengthy, but here's what it does:
Finds the index number of both the Prefix and Key headers.
Modifies the UrlPath by adding the Prefix value if it exists, then adds the Key value in URL-encoded format.
Removes both the Prefix and Key headers from the request.
This ensures that the prefix paths are added as they are, while also ensuring that the Key is URL encoded.
Summary
By combining generated pre-signed URLs from the AWSSimpleStorage external logic connector with REST consume operations in our application, we overcome the following challenges:
We avoid using the external logic connector actions for S3 GetObject and PutObject, which have a request or response payload limit of 5.5MB.
It enables us to retrieve larger objects in in-app event handlers or service actions executed through ODC workflows.
However, this approach has some downsides:
Objects are loaded into the application's memory, which can lead to performance degradation when handling large file sizes.
If the binary data is sent to the frontend application, the entire data is transferred to the client before it can be displayed or used. This means the approach is not suitable for streaming media.
I hope you enjoyed reading this article and that I explained the important parts clearly. If not, please let me know by leaving a comment. I invite you to read the other articles in the series about different patterns for storing and retrieving S3 objects.